0. Description
The final project focus on using OpenCL to perform image convolution. Also should try different optimization method and document the benefits. And this page is great if you are someone new to OpenCL that you can get a better idea in GPU programming optimization.
My GPU card on my laptop is Geforce 9700MGT, which has 32 CUDA cores and 1GB memory.
My GPU card on my laptop is Geforce 9700MGT, which has 32 CUDA cores and 1GB memory.
1. OpenCL
Open Computing Language (OpenCL) is a framework for writing programs that execute across heterogeneous platforms consisting of central processing unit (CPUs), graphics processing unit (GPUs), and other processors. OpenCL includes a language (based on C99) for writing kernels (functions that execute on OpenCL devices), plus application programming interfaces (APIs) that are used to define and then control the platforms. OpenCL provides parallel computing using task-based and data-based parallelism. OpenCL is an open standard maintained by the non-profit technology consortium Khronos Group. It has been adopted by Intel, Advanced Micro Devices, Nvidia, and ARM Holdings.
OpenCL gives any application access to the graphics processing unit for non-graphical computing. Thus, OpenCL extends the power of the graphics processing unit beyond graphics.
OpenCL gives any application access to the graphics processing unit for non-graphical computing. Thus, OpenCL extends the power of the graphics processing unit beyond graphics.
2. Image Convolution using CPU
Convolution is a fundamental operation when it comes to signals and images and other functional analysis. Convolution is a process that combines one signal with a second signal to produce a third signal. Frequently, we say that we have one input signal that is convolved with a mask (aka a filter) to derive the output (filtered) signal.
The following is a basic example for the Algorithm. Here we have an 8x8 signal(i.e., the input image) and we want to convolve it with a 3x3 signal (i.e., the mask or filter).
The following is a basic example for the Algorithm. Here we have an 8x8 signal(i.e., the input image) and we want to convolve it with a 3x3 signal (i.e., the mask or filter).
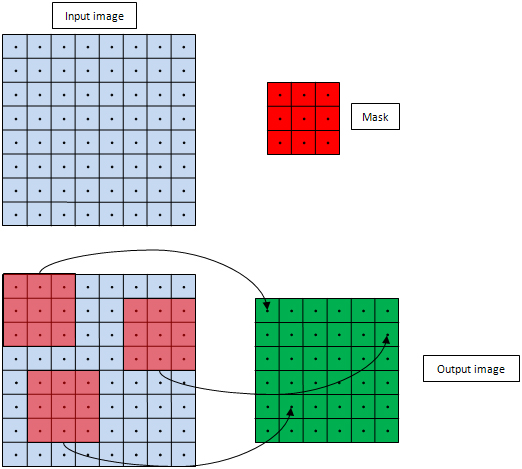
Each element of the output image is generated by (a) placing the filter over the input image, centered at the corresponding pixel location (b) Weighting (multiplying) all the input image pixels covered by the filter with the corresponding filter values, and (c) Accumulating (adding) all the results of step (b).
We perform these steps for all pixels in the output image. So the output image dimensions will be (input_image_width – filter_width + 1) by (input_image_height – filter_width + 1).
The codes for this algorithm in CPU is given below. Here the output image dimensions are width by height, and the input image width is inWidth (equals width + filterWidth - 1) and the input height is (height + filterWidth - 1).
We perform these steps for all pixels in the output image. So the output image dimensions will be (input_image_width – filter_width + 1) by (input_image_height – filter_width + 1).
The codes for this algorithm in CPU is given below. Here the output image dimensions are width by height, and the input image width is inWidth (equals width + filterWidth - 1) and the input height is (height + filterWidth - 1).
- void Convolve(float * pInput, float * pFilter, float * pOutput,
- const int nInWidth, const int nWidth, const int nHeight, const int nFilterWidth
- )
- {
- for (int yOut = 0; yOut < nHeight; yOut++)
- {
- const int yInTopLeft = yOut;//get current y index in input image
- for (int xOut = 0; xOut < nWidth; xOut++)
- {
- const int xInTopLeft = xOut;//get current x index in input image
- float sum = 0;
- for (int r = 0; r < nFilterWidth; r++)
- {
- const int idxFtmp = r * nFilterWidth;//get index in filter image
- const int yIn = yInTopLeft + r;
- const int idxIntmp = yIn * nInWidth + xInTopLeft;
- for (int c = 0; c < nFilterWidth; c++)
- {
- const int idxF = idxFtmp + c;
- const int idxIn = idxIntmp + c;
- sum += pFilter[idxF]*pInput[idxIn];//calculate final result one by one
- }
- } //for (int r = 0...
- const int idxOut = yOut * nWidth + xOut;
- pOutput[idxOut] = sum;
- } //for (int xOut = 0...
- } //for (int yOut = 0...
- }
3. Basic Kernel using GPU
This is a baseline OpenCL convolution kernel that is an almost exact replica of the CPU code for convolution. Each kernel responsible for one entry in the output image. The major difference is that in the OpenCL kernel, we do not need the two outer for-loops that iterate over the output image. Instead, the variables xOut and yOut will be initialized by the get_global_id() call. Also, the variables nWidth and nHeight are left out; they are readily available via the get_global_size() call
The following is the result for this baseline kernel for different size of filter (8 to 64):
- __kernel void Convolve(const __global float * pInput,
- __global float * pFilter,
- __global float * pOutput,
- const int nInWidth,
- const int nFilterWidth)
- {
- const int nWidth = get_global_size(0);
- const int xOut = get_global_id(0);
- const int yOut = get_global_id(1);
- const int xInTopLeft = xOut;
- const int yInTopLeft = yOut;
- float sum = 0;
- for (int r = 0; r < nFilterWidth; r++)
- {
- const int idxFtmp = r * nFilterWidth;
- const int yIn = yInTopLeft + r;
- const int idxIntmp = yIn * nInWidth + xInTopLeft;
- for (int c = 0; c < nFilterWidth; c++)
- {
- const int idxF = idxFtmp + c;
- const int idxIn = idxIntmp + c;
- sum += pFilter[idxF]*pInput[idxIn];
- }
- } //for (int r = 0...
- const int idxOut = yOut * nWidth + xOut;
- pOutput[idxOut] = sum;
- }
The following is the result for this baseline kernel for different size of filter (8 to 64):
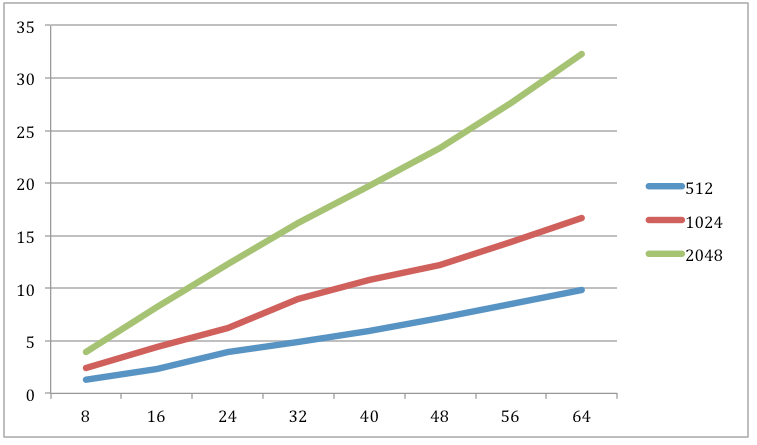
We can see that more computation time for the larger input and filter, and also the slope of larger size input is larger, I thinks it is because the limit of the number of cores in GPU then each core have to change thread so frequent.
4. Unrolled Loop Kernel
This section I tried loop unrolling as a technique to reduce the computation time for convolution.
For a filter of width fw, for each entry in the output image, the statements in the innermost loop are run (fw x fw) times. That is, the loop condition test and the ensuing branching happen (fw x fw) times. While this cost may be tiny for small filters (only 4 iterations for 2x2 filters), it becomes significant as the filter width increases (1024 iterations for 32x32 filter). And the main feature for this technique is to reduce the loop count.
Following is the convolution kernel, with four iterations of the innermost loop unrolled. The two changes are that (a) the innermost loop statements are repeated four times, and (b) there is another loop at the end to handle the remainder of the iterations when filter width is not an even multiple of four.
For a filter of width fw, for each entry in the output image, the statements in the innermost loop are run (fw x fw) times. That is, the loop condition test and the ensuing branching happen (fw x fw) times. While this cost may be tiny for small filters (only 4 iterations for 2x2 filters), it becomes significant as the filter width increases (1024 iterations for 32x32 filter). And the main feature for this technique is to reduce the loop count.
Following is the convolution kernel, with four iterations of the innermost loop unrolled. The two changes are that (a) the innermost loop statements are repeated four times, and (b) there is another loop at the end to handle the remainder of the iterations when filter width is not an even multiple of four.
- __kernel void Convolve_Unroll(const __global float * pInput,
- __global float * pFilter,
- __global float * pOutput,
- const int nInWidth,
- const int nFilterWidth)
- {
- const int nWidth = get_global_size(0);
- const int xOut = get_global_id(0);
- const int yOut = get_global_id(1);
- const int xInTopLeft = xOut;
- const int yInTopLeft = yOut;
- float sum = 0;
- for (int r = 0; r < nFilterWidth; r++)
- {
- const int idxFtmp = r * nFilterWidth;
- const int yIn = yInTopLeft + r;
- const int idxIntmp = yIn * nInWidth + xInTopLeft;
- int c = 0;
- while (c <= nFilterWidth-4)
- {
- int idxF = idxFtmp + c;
- int idxIn = idxIntmp + c;
- sum += pFilter[idxF]*pInput[idxIn];
- idxF++;
- idxIn++;
- sum += pFilter[idxF]*pInput[idxIn];
- idxF++;
- idxIn++;
- sum += pFilter[idxF]*pInput[idxIn];
- idxF++;
- idxIn++;
- sum += pFilter[idxF]*pInput[idxIn];
- c += 4;
- }
- for (int c1 = c; c1 < nFilterWidth; c1++)
- {
- const int idxF = idxFtmp + c1;
- const int idxIn = idxIntmp + c1;
- sum += pFilter[idxF]*pInput[idxIn];
- }
- } //for (int r = 0...
- const int idxOut = yOut * nWidth + xOut;
- pOutput[idxOut] = sum;
- }
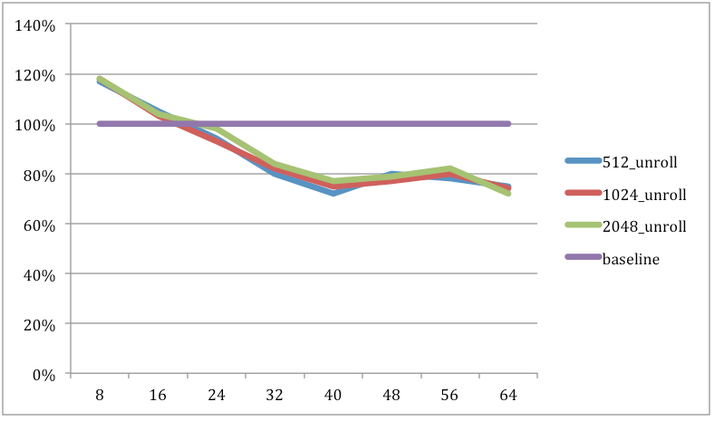
The results are expected: the unrolled kernel does not improve the timing when the filter width is small since there are only a few iterations to be saved by unrolling. As the filter size grows, it helps improve speed by as much as 28%.
5. Kernel with Invariants
Fow the previous kernel is all in a generic way that they will work for all filter sizes; the filter width is passed as an argument. Now consider a kernel for a specific filter size, say 5x5. We can now unroll the inner loop five times and get rid of the loop condition altogether.
This new kernel Convolve_Def will use the invariant FILTER_WIDTH instead of the argumentint filterWidth taken by the kernel Convolve.
This new kernel Convolve_Def will use the invariant FILTER_WIDTH instead of the argumentint filterWidth taken by the kernel Convolve.
- __kernel void Convolve_Def(const __global float * pInput,
- __global float * pFilter,
- __global float * pOutput,
- const int nInWidth,
- const int nFilterWidth)
- {
- const int nWidth = get_global_size(0);
- const int xOut = get_global_id(0);
- const int yOut = get_global_id(1);
- const int xInTopLeft = xOut;
- const int yInTopLeft = yOut;
- float sum = 0;
- for (int r = 0; r < FILTER_WIDTH; r++)
- {
- const int idxFtmp = r * FILTER_WIDTH;
- const int yIn = yInTopLeft + r;
- const int idxIntmp = yIn * nInWidth + xInTopLeft;
- for (int c = 0; c < FILTER_WIDTH; c++)
- {
- const int idxF = idxFtmp + c;
- const int idxIn = idxIntmp + c;
- sum += pFilter[idxF]*pInput[idxIn];
- }
- } //for (int r = 0...
- const int idxOut = yOut * nWidth + xOut;
- pOutput[idxOut] = sum;
- }
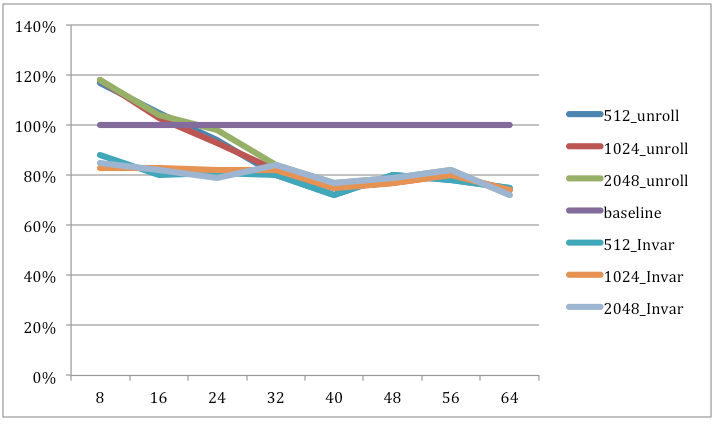
We can see that defining the filter width as an invariant helps the kernel gain about 26% performance, particularly for small kernel sizes.
We can use the same technique in the unrolled kernels (Convolve_Unroll with the invariant becomes Convolve_Def_Unroll, and Convolve_UnrollIf yieldsConvolve_Def_UnrollIf
We can use the same technique in the unrolled kernels (Convolve_Unroll with the invariant becomes Convolve_Def_Unroll, and Convolve_UnrollIf yieldsConvolve_Def_UnrollIf
6. Using the __constant space
The __constant space is a memory region where work-items have faster access to the data. Using the __constant memory yields around 5% speed gain. What's interesting, though, is that all we need to do to implement this optimization is replace __global with __constant. The limitation, of course, is that OpenCL kernels can only take a limited number of __constant arguments and buffers stored in the __constant space have limited size (queriable, but at least 64 kb). In other words, if a set of the kernel arguments won't exceed 64 kb and they won't be modified, there's no reason not to allocate them in __constant space.
- __kernel void Convolve(const __global float * pInput,
- __constant float * pFilter,
- __constant float * pOutput,
- const int nInWidth,
- const int nFilterWidth)
- {
- const int nWidth = get_global_size(0);
- const int xOut = get_global_id(0);
- const int yOut = get_global_id(1);
- const int xInTopLeft = xOut;
- const int yInTopLeft = yOut;
- float sum = 0;
- for (int r = 0; r < nFilterWidth; r++)
- {
- const int idxFtmp = r * nFilterWidth;
- const int yIn = yInTopLeft + r;
- const int idxIntmp = yIn * nInWidth + xInTopLeft;
- for (int c = 0; c < nFilterWidth; c++)
- {
- const int idxF = idxFtmp + c;
- const int idxIn = idxIntmp + c;
- sum += pFilter[idxF]*pInput[idxIn];
- }
- } //for (int r = 0...
- const int idxOut = yOut * nWidth + xOut;
- pOutput[idxOut] = sum;
- }
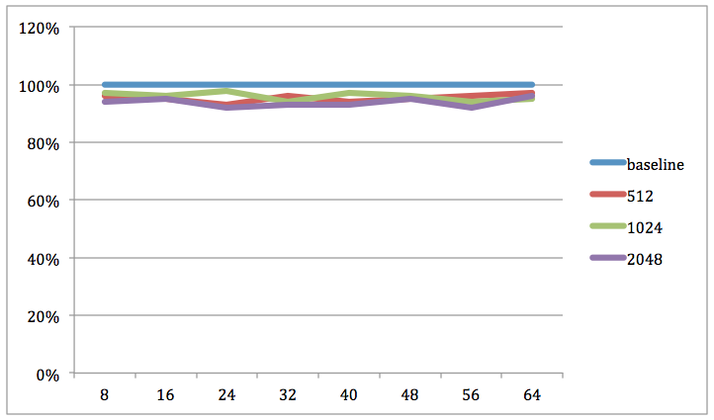
7. Caching in the __local space
The OpenCL __local space is a very fast memory that can be shared between work-items belonging to the same work-group. So if your kernel needs to access the same values in __global memory many times, it is a good idea to cache the information using __local (if the access pattern is known beforehand).
Following is a strategy to cache the image in __local space:
Following is a strategy to cache the image in __local space:
- Copy all data that the work-items are going to use into __local space;
- Access the cached data to perform the calculations;
- Output the answer into the correct position.
8. Reference
http://www.cmsoft.com.br/index.php?option=com_content&view=category&layout=blog&id=142&Itemid=201
a great study case for image convolution using opencl
http://developer.amd.com/sdks/AMDAPPSDK/documentation/ImageConvolutionOpenCL/Pages/ImageConvolutionUsingOpenCL.aspx
a step by step tutorial from AMD for image convolution using opencl with a 4 core CPU
a great study case for image convolution using opencl
http://developer.amd.com/sdks/AMDAPPSDK/documentation/ImageConvolutionOpenCL/Pages/ImageConvolutionUsingOpenCL.aspx
a step by step tutorial from AMD for image convolution using opencl with a 4 core CPU
